R memiliki banyak struktur data. Di sini, dikenalkan beberapa yang sering digunakan saja, sebagai permulaan sebelum terjerumus terlalu dalam dengan R. Bahaya!
Vektor
Struktur data ini merupakan struktur data yang paling banyak digunakan dalam R. Bisa dikatakan vektor merupakan struktur data yang utama dalam R. Vektor adalah kumpulan nilai yang disebut elemen, yang memiliki tipe data atau mode yang sama. Kita dapat membuat vektor dari elemen-elemen berjenis numerik, string, atau bilangan bulat. Yang penting semua elemen dalam satu vektor harus berjenis sama. Elemen dalam vektor ini dapat diberi nama. Sesuka-suka kita, asal kita tahu, untuk apa.
nilai <- c(statistik = 89, fisika = 95, ilmukomunikasi = 100)
#Menampilkan isi vektor nilai
nilai
#Menampilkan isi ke-2
nilai[2]
#Mengambil dan menampilkan isi dengan nama fisika
nilai["fisika"]
> #Membuat named vector dengan nama nilai
> nilai <- c(statistik = 89, fisika = 95, ilmukomunikasi = 100)
>
> #Menampilkan isi variable nilai
> nilai
statistik fisika ilmukomunikasi
89 95 100
>
> #Menampilkan isi ke-2 dari vektor nilai
> nilai[2]
fisika
95
>
> #Mengambil dan menampilkan isi dengan nama fisika
> nilai["fisika"]
fisika
95
Skalar
Skalar atau nilai individual. Struktur data ini bisa dikatakan tidak benar-benar eksis di dalam R, karena skalar (scalar) dapat dinyatakan sebagai vektor dengan panjang 1.
> x <- 6 > x [1] 6
Pada x diberikan skalar dengan nilai 6. Perhatikan penanda [1] pada keluaran konsol interaktif R. ini menandakan R menganggap x sebagai vektor dengan elemen sebanyak 1.
Karakter string
Contoh berikut memperlihatkan struktur data karakter string. Struktur data ini merupakan vektor atau skalar dengan mode string.
> x <- c(5,12,13)
> x
[1] 5 12 13
> length(x)
[1] 3
> mode(x)
[1] "numeric"
> y <- "abc"
> y
[1] "abc"
> length(y)
[1] 1
> mode(y)
[1] "character"
> z <- c("abc","29 88")
> length(z)
[1] 2
> mode(z)
[1] "character"
Contoh pertama memberikan vektor x yang terdiri dari tiga elemen dengan mode numerik. Kemudian vektor y adalah vektor dengan string tunggal. Bagaimana apabila vektor terdiri dari karakter string dan numerik? R akan mengubahnya menjadi karakter. Seperti contoh berikut
> x<-c("abc",1,3)
> x
[1] "abc" "1" "3"
> x<-c(1,2,"abc",1,3)
> x
[1] "1" "2" "abc" "1" "3"
R memiliki banyak fungsi untuk mengelola string. Beberapa berurusan dengan penggabungan string-string atau pemisahannya. Ini contohnya.
> u <- paste(“abc”,”de”,”f”) # menggabungkan string > u
[1] “abc de f”
> v <- strsplit(u,” “) # memisahkan string berdasarkan karakter kosong. > v
[[1]]
[1] “abc” “de” “f”
[/code]
Matriks
Sesuai namanya, struktur data ini memiliki makna yang sama dengan matrik dalam matematika: yaitu kotak bilangan yang tersusun sebagai array. Pada dasarnya matriks merupakan vektor, dengan tambahan atribut, yaitu nomor kolom dan nomor baris. Berikut adalah contoh dari matriks.
> m <- rbind(c(1,4),c(2,2)) > m [,1] [,2] [1,] 1 4 [2,] 2 2 > m % * % c(1,1) [,1] [1,] 5 [2,] 4
Contoh pertama menggunakan fungsi rbind untuk mengabungkan dua vektor menjadi matriks yang digabungkan menjadi baris-baris. Fungsi cbind dapat digunakan apabila hendak menggabungkan suatu vektor sebagai kolom dari suatu matriks. Terakhir dari contoh di atas adalah melakukan perkalian matriks antara m dengan vektor (1,1). Untuk mengakses nilai elemen tertentu dari matriks dapat dilakukan dengan kurung siku [a,b] untuk mengambil nilai baris ke-a dan kolom ke-b.
Contoh
> m[1,2] [1] 4 > m[2,2] [1] 2
Di dalam R, selain elemen tunggal, juga dapat dilakukan pengaksesan untuk kolom atau baris. Seperti contoh berikut
> m[1,] # row 1 [1] 1 4 > m[,2] # column 2 [1] 4 2
List
Sebagaimana vektor, list juga merupakan wadah untuk menyimpan nilai. Perbedaannya adalah pada list, elemen list dapat bertipe apa saja, dan tidak harus sama. Elemen dari suatu list dapat diakses dengan mengambil nama list dan nama elemen dari list yang dihubungkan dengan lambang “$”.
> x <- list(u=2, v="abc") > x $u [1] 2 $v [1] "abc" > x$u [1] 2
Ekspresi x$u merujuk pada komponen u dalam list x. List x ini memiliki dua komponen yaitu u dan v.
Secara umum, list digunakan untuk menampung beberapa hasil yang dikeluarkan oleh suatu fungsi. Contoh pada fungsi hist(), misal kita gunakan gugus data bawaan dari R yaitu Nile, dan membuat histogram dari data tersebut.
data(Nile) #untuk mengaktifkan gugus data Nile hist(Nile) #membuat histogram dari data Nile x<-hist(Nile)
Apakah x? Ternyata x merupakan list dengan komponen-komponen yang dihasilkan dari fungsi hist(). Mari kita lihat.
Selain menghasilkan keluaran berupa histogram
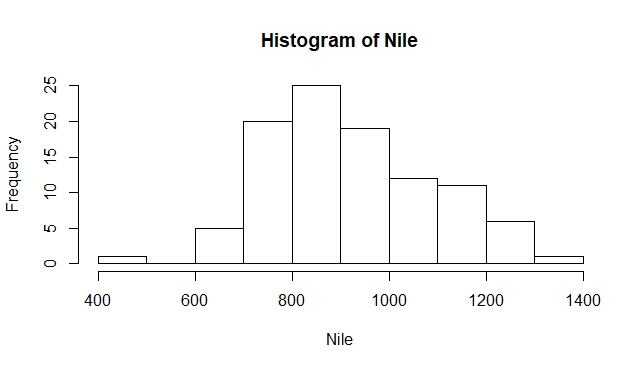
fungsi tersebut juga menghasilkan objek x yang berbentuk list yang dapat kita panggil mana kita suka.
> print(x) $breaks [1] 400 500 600 700 800 900 1000 1100 1200 1300 1400 $counts [1] 1 0 5 20 25 19 12 11 6 1 $density [1] 0.0001 0.0000 0.0005 0.0020 0.0025 0.0019 0.0012 0.0011 0.0006 0.0001 $mids [1] 450 550 650 750 850 950 1050 1150 1250 1350 $xname [1] "Nile" $equidist [1] TRUE attr(,"class") [1] "histogram"
Abaikan apa makna dari komponen-komponen tersebut. Kita masih dalam tahap kenalan awal. Nanti juga ada penjelasan di bagian lain. Hal yang menarik adalah, bahwa selain membuat histogram, fungsi hist () juga menyimpan komponen nilai-nilai lain dalam bentuk list. Agar tampilan list ini lebih ringkas sehingga lebih mudah dibaca, dapat menggunakan perintah str.
> str(x)
List of 6
$ breaks : int [1:11] 400 500 600 700 800 900 1000 1100 1200 1300 ...
$ counts : int [1:10] 1 0 5 20 25 19 12 11 6 1
$ density : num [1:10] 0.0001 0 0.0005 0.002 0.0025 0.0019 0.0012 0.0011 0.0006 0.0001
$ mids : num [1:10] 450 550 650 750 850 950 1050 1150 1250 1350
$ xname : chr "Nile"
$ equidist: logi TRUE
- attr(*, "class")= chr "histogram"
<code>str</code> adalah singkatan dari struktur. Fungsi ini dapat digunakan untuk memeriksa struktur pada setiap objek dalam R. Biar tambah bingung.
<h3>f. Data Frame</h3>
Gugus data tertentu memiliki beberapa macam tipe data. Misalnya gugus data yang didapat dari hasil survei terhadap pengunjung dari suatu restoran. Gugus dapat terdiri dari nama, jenis kelamin, usia, pekerjaan, jumlah pembelian. Karena tipe datanya tidak seragam, tidak dapat menggunakan struktur data matriks. Data frame adalah merupakan list, dengan setiap komponen di dalamnya menjadi suatu kolom dalam suatu “matriks”. Kita dapat membuat sebuah data frame dengan cara sebagai berikut.
> d<-data.frame(list(anak=c("banu","dara"),umur=c(13,11)))
> str(d)
'data.frame': 2 obs. of 2 variables:
$ anak: Factor w/ 2 levels "banu","dara": 1 2
$ umur: num 13 11
> print(d)
anak umur
1 banu 13
2 dara 11
> d$umur
[1] 13 11
> d[1,]
anak umur
1 banu 13
Hasil pembacaan gugus data dari file atau database, secara umum menghasilkan suatu data frame.
Classes
Struktur data ini yang tampak paling rumit. Begini urutan penjelasannya. Karena R merupakan bahasa pemrograman dengan paradigma OOP (object oriented programming), jadi data dan strukturnya juga merupakan objek. Dalam konsep OOP, object merupakan instances (contoh) dari classes.
Begini, R merupakan bahasa yang diturunkan dari bahasa S. Apakah kelak akan ada juga bahasa T sebagai cucu dari bahasa S? Jadi nama dari struktur data classes ini adalah S3. Yaitu nama bahasa mamaknya S, untuk versi ke-3. Sebagian besar R berdasarkan pada kelas ini. Instance dari kelas ini adalah list dalam R, tetapi dengan tambahan atribut: nama kelas. Contoh sebelum ini memperlihatkan bahwa fungsi hist memiliki beberapa macam nilai keluaran yang non grafis, yang termuat di dalam suatu list. Di dalam list tersebut ada komponen break dan count. Juga ada komponen attribute, yang secara spesifik menyatakan class dari list, yang dinamakan histogram.
Lalu, apabila kelas S3 ini hanyalah list, kenapa bikin ribet dinamakan berbeda segala? Jawabannya adalah bahwa class ini digunakan oleh fungsi generik. Fungsi generic adalah keluarga fungsi yang dapat melayani tujuan yang serupa tetapi dengan cara tertentu pada kelas-kelas yang spesifik. Fungsi generik yang umum adalah summary(). Pengguna R yang membutuhkan fungsi statistik, semisal hist(), tetapi tidak tahu bagaimana mengelola keluaran dari fungsi tersebut dapat memanggil fungsi summary() terhadap output dari fungsi hist(). Fungsi summary() ini tidak hanya menangani output tersebut sebagai list, tetapi sebagai kelas S3. Fungsi summary(), pada dasarnya merupakan keluarga dari fungsi pembuat ringkasan (summary-making) yang masing-masing menangani objek-objek dari kelas yang berbeda. Saat fungsi ini dipanggil untuk menangani suatu keluaran dari fungsi R, akan dicari fungsi summary yang bersesuaian dengan kelas dari argumen yang dimasukkan. summary() dengan argumen berupa output dari hist() akan berbeda dengan fungsi untuk melayani argumen berupa output dari fungsi lm().
Tambah bingung, jadi kelas ini buat apa ya? Pake dulu aja deh…